Quel est le point commun entre les entreprises Shift Technology, ContentSquare, Damae Medical et Welcome to the Jungle ?
Il s’agit de startups françaises dont les fondateurs sont majoritairement des hommes issus de grandes écoles d’ingénieurs ou de commerce ?
Non ! Enfin… oui, mais ce n’était pas la réponse attendue !
Ce sont des startups françaises avec une forte composante data dans leur activité et qui ont levé plusieurs millions d’euros ces dernières années :
- Welcome to the Jungle - Série C - 50 millions € (février 2023)
- ContentSquare - Série F - 600 millions $ (juillet 2022) - Analyse de l’expérience utilisateur sur des plateformes en ligne
- Owkin - Série B - 80 millions $ (juin 2022) - Optimiser le traitement de chaque patient
- Damae Medical - Série A - 5 millions € (février 2022) - Détection et surveillance non-intrusive de cancers de la peau en temps réel
- Shift Technology - Série D - 220 millions $ (mai 2021) - Détection de fraude à l’assurance
- Libeo - Série A - 20 millions € (février 2021) - Centralisation des factures entrantes et sortantes
- Uptime - Série B - 7 millions € (octobre 2019) - Maintenance prédictive d’ascenseurs
Ces entreprises ont souvent besoin d’importants moyens financiers afin de concrétiser leurs promesses ambitieuses. La data et l’intelligence artificielle - souvent évoquées de manière interchangeable - sont au cœur de ces promesses.
Mais la data et l’intelligence artificielle justifient-elles vraiment de tels afflux d’argent ?
Que sont-elles et à quoi servent-elles ?
Data et intelligence artificielle : ce qu’elles sont l’une pour l’autre
Par abus de langage, on utilise souvent data et intelligence artificielle sans vraiment faire de différence entre les deux. Ce n’est pas un problème, sauf lorsqu’on essaie d’expliquer de quelle manière elles fonctionnent ensemble.
Imaginons que je souhaite déterminer le montant mensuel de mes dépenses alimentaires.
Dans un premier temps, je vais rassembler mes relevés de carte bleue de ces derniers mois.
Puis, pour estimer mes dépenses alimentaires, je vais discriminer les dépenses alimentaires (restaurant, supermarché, etc) des autres dépenses (transports, vêtements, etc) en m’appuyant sur les relevés de carte bleue. Une stratégie simple est de m’appuyer sur le débiteur pour décider si pour chaque ligne de mon relevé de carte bleue, je prends en compte le montant dépensé.
- La data désigne l’ensemble des données associées à un contexte donné : dans cet exemple, il s’agit des relevés de carte bleue.
- Une intelligence artificielle permet de résoudre un problème ou de répondre à une question, en tirant parti de la data disponible : toujours dans cet exemple, il s’agit de la procédure qui me permet de calculer mes dépenses alimentaires à partir de mes relevés de carte bleue et des débiteurs à prendre en compte.
En résumé, une bonne intelligence artificielle est capable de s’acquitter d’une tâche intellectuelle accomplie traditionnellement par un humain :
- automatiquement
- de manière satisfaisante
- en un temps réduit
A priori, la data et l’intelligence artificielle constituent donc souvent une cible d’investissement relativement sûre car elles permettent de réduire les coûts et d’augmenter l’efficacité d’exécution sur une activité pré-existante.
Je dis a priori car plusieurs écueils de taille justifient une certaine prudence :
- la data n’est pas toujours disponible pour développer une intelligence artificielle résolvant notre problème (données non-observables ou légalement non-utilisables par exemple)
- la résolution du problème peut nécessiter de garantir une certaine précision (quasi-impossible)
Laissons ces obstacles de côté et penchons nous plutôt sur un problème concret pour bien comprendre ce que sont la data science, les problèmes d’intelligence artificielle et la nature des liens qui les unissent !
Intelligence artificielle, vente de baguettes et prédiction : un cas concret
Fred est boulanger, son pain est réputé et les clients sont légion. Cent baguettes sont produites par jour dans sa boulangerie, sauf le mercredi, jour de fermeture hebdomadaire.
Il y a tout de même deux choses qui ennuient Fred :
- Certains soirs, il se retrouve avec des dizaines de pains non vendus.
- Certains jours, il doit se fournir en catastrophe chez son concurrent d’à côté pour éviter que ses clients ne repartent bredouilles. Même si ses clients repartent avec du pain - l’essentiel selon Fred - 1° le pain de son concurrent est nettement inférieur et 2° ça lui éclate sa marge.
Fred est obsédé par cette question : combien de pains seront vendus le jour suivant dans ma boulangerie ?
Cette question, c’est le problème à résoudre. En l’occurrence, il s’agit d’une question très précise, qui attend pour réponse la prédiction d’une quantité. Ce sont des caractéristiques essentielles pour être une bonne question de data science, mais elles ne suffisent pas.
Cela dit, on ne va pas se mentir, ça sent plutôt bon :-)
Grâce à son logiciel de caisse, Fred a pu récupérer de nombreuses données depuis l’ouverture de sa boulangerie il y a 8 ans, notamment, le nombre de baguettes cuites par jour et le nombre de baguettes vendues par jour. Il dispose aussi des dates et heure de chaque achat de produit, ainsi que les numéros de tickets associés.
Alors oui, ça y est, on a de la data en quantité, et en plus ce sont des données qui ont un rapport avec ce qu’on cherche à prédire ! Mais nous y reviendrons plus tard.
Une première approche : l’observation
Se creuser la tête
Après avoir passé quelques heures à regarder son tableau de ventes, Fred a mal à la tête et il n’est pas beaucoup plus avancé.
Pour se faire une idée, il trace l’évolution du nombre quotidien de baguettes vendues sur l’ensemble des 12 dernières semaines 1.
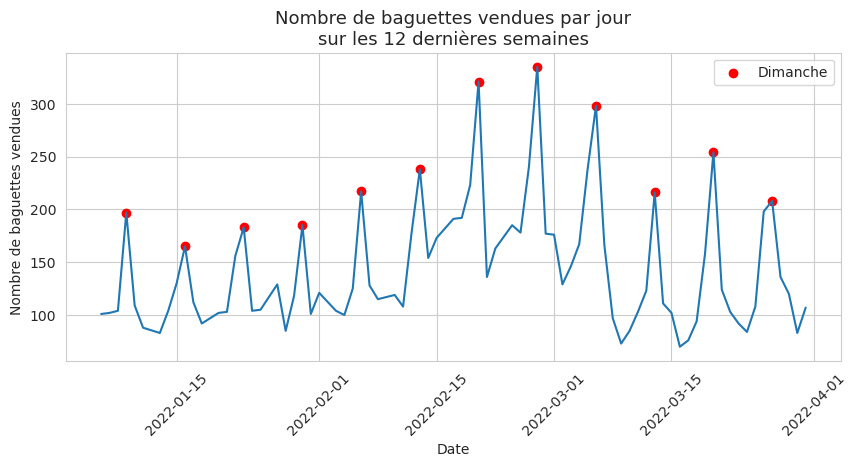
Il remarque immédiatement plusieurs choses :
- Chaque semaine, le dimanche est la meilleure journée de ventes avec un nombre de ventes deux fois plus élevé que la moyenne en semaine.
- Les semaines se suivent et se ressemblent mais il remarque une forte augmentation des ventes sur une période de 2/3 semaines qui semble correspondre aux vacances scolaires.
Fred en tire une conclusion : il doit tenir compte des vacances scolaires pour revoir à la hausse ses estimations.
Cette idée de “faire un dessin”, répétée par nombre de professeurs de mathématiques à leurs élèves en train de sécher devant leur exercice de géométrie, est très importante en data. Elle permet à l’humain d’une part de comprendre la situation à laquelle il est confronté, et d’autre part de générer des idées pour y faire face. C’est le domaine de la visualisation de données, à la croisée des sciences cognitives, du graphisme et du design.
Fort de ces observations, Fred met à jour son planning de production.
| Jour de la semaine | Hors vacances scolaires | Pendant les vacances scolaires |
|---|---|---|
| Lundi, Mardi, Jeudi, Vendredi | 100 | 150 |
| Samedi | 150 | 215 |
| Dimanche | 200 | 300 |
Là où il n’y avait aucune règle, il existe maintenant deux variables qui vont faire évoluer le nombre de baguettes à produire :
- le jour de la semaine
- le fait d’être ou non en période de vacances scolaires.
Sans forcément le savoir, Fred vient de donner naissance à une intelligence artificielle : il a automatisé un processus intellectuel en le rendant complètement autonome - n’importe qui avec cette description peut reproduire ce planning, sans besoin d’aucune autre connaissance.
Tout ça pour quoi ?
Hourra, on a obtenu une solution 1° ultra-rapide, 2° automatique et 3° produisant un résultat satisfaisant. Oui, une intelligence artificielle vient de naître !
Mais il reste une question de taille : apporte-t-elle vraiment quelque chose ?
En d’autres termes, sur quel critère doit-on se reposer pour dire que notre intelligence artificielle est performante ?
La réponse est simple : à nous de décider.
On pourrait considérer le point de vue anti-gaspillage et prendre pour critère le nombre de baguettes invendues.
Mais Fred dirige un business, et ce qui compte, c’est d’abord d’améliorer la rentabilité. Fred estime donc les pertes liées à une baguette invendue (0,30 €), les pertes liées à une baguette achetée à son concurrent (0,10€) et il peut ainsi associer une perte à chaque journée.
Notre boussole, l’objectif qui nous mobilise sur un problème donné, c’est la métrique d’évaluation.
Pour évaluer la pertinence de notre intelligence artificielle, nous allons comparer sa performance selon ces deux critères sur la période passée de 12 semaines :
| Mode de planification | Métrique “anti-gaspillage” | Métrique business “Fred” |
|---|---|---|
| Approche initiale 100 baguettes / jour | 198 baguettes invendues | 421 € de pertes |
| Approche “intelligence artificielle de Fred” | 459 baguettes invendues | 251 € de pertes |
Fred a intuitivement développé une intelligence artificielle qui permet de réduire les pertes financières, tandis que son approche historique permet de mieux réduire le nombre de baguettes invendues.
On vient de tester notre intelligence artificielle sur une période passée - donc avec des données historiques déjà disponibles - cela nous permet d’évaluer notre nouvelle approche rapidement sans avoir à la mettre en pratique, tout en la comparant à l’approche traditionnelle. C’est une méthode couramment utilisée dans le métier, qui répond au doux nom de backtesting.
Une deuxième approche : contre l’overdose de variables, place à l’algorithme !
En testant son approche sur une année entière, Fred se rend compte que sa stratégie ne fonctionne pas toujours aussi bien :
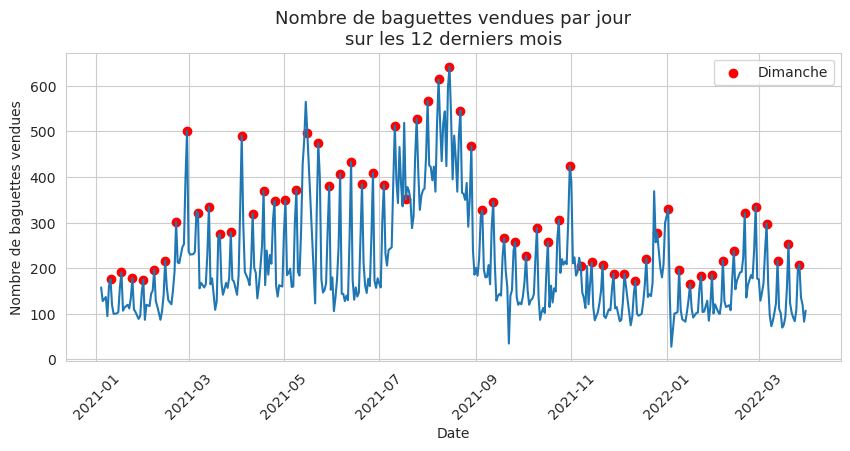
Fred se voit obligé de multiplier les règles et les exceptions pour en arriver à une intelligence artificielle impossible à maintenir (vacances d’été, les foires locales, les festivals, nombre de boulangeries ouvertes dans un rayon d’un km, etc). On peut tenter de construire quelques règles simples à partir de l’observation, comme Fred, mais très rapidement, cette approche devient intenable, les variables deviennent trop nombreuses.
C’est là que les algorithmes de machine learning ou apprentissage statistique (oui, c’est moins stylé en Français) entrent en jeu.
Bon, l’air de rien, je viens de lâcher deux gros mots : algorithme et machine learning. Ne partez pas tout de suite, je vous explique tout de suite de quoi il s’agit.
Qu’est-ce qu’un algorithme ?
Un algorithme n’est rien de moins qu’une recette claire permettant, à partir de différents éléments en entrée, d’obtenir un résultat en sortie, exactement comme une recette de cuisine. L’intérêt des algorithmes vient du fait qu’une fois programmés, ils peuvent être exécutés par des ordinateurs.
L’intelligence artificielle de Fred est un exemple d’algorithme très simple exécutable par un humain :
| Entrée | Recette | Sortie |
|---|---|---|
| Jour de la semaine & période de vacances scolaires | Se référer au planning de production (tableau défini plus haut) | Nombre de baguettes à cuire le lendemain |
| Œufs, beurre, farine, chocolat | Recette de gâteau au chocolat | Gâteau au chocolat |
Dire qu’un algorithme n’est rien de plus qu’une recette n’a rien de révolutionnaire. Pour être un chouia plus précis, Donald Knuth, un des pères fondateurs de l’algorithmique moderne, a proposé 5 propriétés élémentaires que doit posséder un algorithme :
- Finitude : l’algorithme doit démarrer et s’arrêter, en un temps raisonnable (notion toute relative qui dépend de la nature de l’algorithme)
- Précision : aucune étape de l’algorithme ne peut être sujette à interprétation
- Entrées : l’algorithme débute ses calculs depuis un état initial qui peut être fourni par des valeurs en entrée avant le démarrage de celui-ci
- Sorties : l’algorithme produit un résultat en rapport avec les valeurs en entrée
- Efficacité : les étapes d’un algorithme doivent être suffisamment simples pour être exprimées en texte clair, compréhensible par un humain
On notera bien évidemment la deuxième et la cinquième propriété qui peuvent souvent manquer lorsqu’on a affaire à une recette de cuisine !
C’est quoi le machine learning ?
Un point important pour comprendre l’algorithme de machine learning, c’est qu’il comporte en fait deux “recettes” :
- une phase d’apprentissage : création d’une recette de planification à partir des données historiques de baguettes vendues
- une phase de prédiction : application de la recette obtenue suite à l’apprentissage pour donner le nombre de baguettes à cuire le lendemain
On peut exprimer ces phases de la même manière que précédemment.
Phase d’apprentissage
| Entrée | Recette | Sortie |
|---|---|---|
| Jour de la semaine, période de vacances scolaires, (nombreuses) autres variables | Algorithme de machine learning | Recette de planification |
Phase de prédiction
| Entrée | Recette | Sortie |
|---|---|---|
| Jour de la semaine, période de vacances scolaires, (nombreuses) autres variables | Recette de planification | Nombre de baguettes à cuire le lendemain |
La phase d’apprentissage, qui a lieu avant toute prédiction, permet d’aboutir à une recette de planification qui sera ensuite utilisée dans la phase de prédiction.
Seulement ce ne sera pas un planning de production lisible comme celui de Fred, qui reflète la réflexion de celui-ci autour du problème. Ce sera plutôt comme une boîte noire magique et illisible pour un humain, qui aura appris à prédire au plus juste durant la phase d’apprentissage. En pratique, la recette de planification ainsi obtenue est illisible pour un humain, mais potentiellement très efficace dans sa tâche de prédiction.
En résumé
Ce qu’on retient
Reprenons tranquillement maintenant que les premières briques sont posées :
- la data sert à observer et comprendre
- l’intelligence artificielle sert à résoudre un problème, et elle peut être construite de 2 manières différentes :
- construction artisanale par un humain (peu de variables)
- construction automatique par un algorithme (nombre de variables potentiellement élevé)
- l’algorithme de machine learning permet d’entraîner une intelligence artificielle puissante à l’aide de la data
Notre cas concret - largement simplifié - nous permet toutefois de saisir comment ces différents concepts fonctionnent ensemble.
Par ailleurs, il nous permet d’illustrer certaines situations rendant les solutions d’intelligence artificielles inopérantes :
-
Fred pourrait se rendre compte que les ventes sont largement influencées par les stagiaires d’un centre de formation et observer de nombreux pics de ventes imprévisibles - car la donnée du nombre de stagiaires passés et à venir sont inaccessibles pour Fred.
-
Fred pourrait n’accepter d’utiliser l’intelligence artificielle que si celle-ci garantit une prédiction fiable à 10% près, ce qui est impossible à contrôler.
Intelligence artificielle et levées de fonds
Avec la perspective de gains rapides, intégrer de l’intelligence artificielle au cœur de n’importe quelle industrie a suffi pendant un temps à ouvrir en grand les vannes du financement. Malgré l’émergence d’un certain discernement, la mode de l’intelligence artificielle s’est transformée en tendance durable. Parce que dans de très nombreux cas, les intelligences artificielles fonctionnent redoutablement bien : alors que les robots remplacèrent il y a quelques décennies les ouvriers sur des chaines de montage, les intelligences artificielles remplacent à présent des experts sur des tâches de plus en plus sophistiquées.
Elles ne sont toutefois pas systématiquement gages de succès pour les entreprises qui les utilisent :
- soit parce que le problème ne s’y prête pas
- soit par manque de données
- soit parce que le coût financier du développement, de la mise en œuvre et de la maintenance de l’intelligence artificielle est trop élevé (article à venir)
Avec sa capacité grandissante à automatiser des tâches intellectuelles de plus en plus complexes et à déchaîner l’imaginaire collectif, l’intelligence artificielle a encore de très nombreuses levées de fonds devant elle.